Adding MLflow to Anaconda Enterprise 5#
You can install MLflow as an optional component of Anaconda Enterprise.
Prerequisites#
You must have managed persistence enabled.
Set environment variables#
Setting environment variables allows MLflow to be accessible from all sessions, deployments, and schedules. This also sets the deployment-wide values for the MLflow tracking server endpoint.
Connect to your instance of Anaconda Enterprise. Get help from your IT administrator with this step if necessary.
View a list of your configmaps by running the following command:
kubectl get cm
Edit the anaconda-enterprise-env-var-config.yml file.
kubectl edit cm anaconda-enterprise-env-var-config
Include the following lines:
# Replace <AE5_FQDN> with your Anaconda Enterprise fully qualified domain name MLFLOW_DISABLE_ENV_MANAGER_CONDA_WARNING: "TRUE" MLFLOW_TRACKING_URI: "https://mlflow.<AE5_FQDN>" MLFLOW_REGISTRY_URI: "https://mlflow.<AE5_FQDN>"
Note
If your
ENV_VAR_PLACEHOLDER: fooentry still exists, replace it now.Here is an example of what your file might look like when complete:
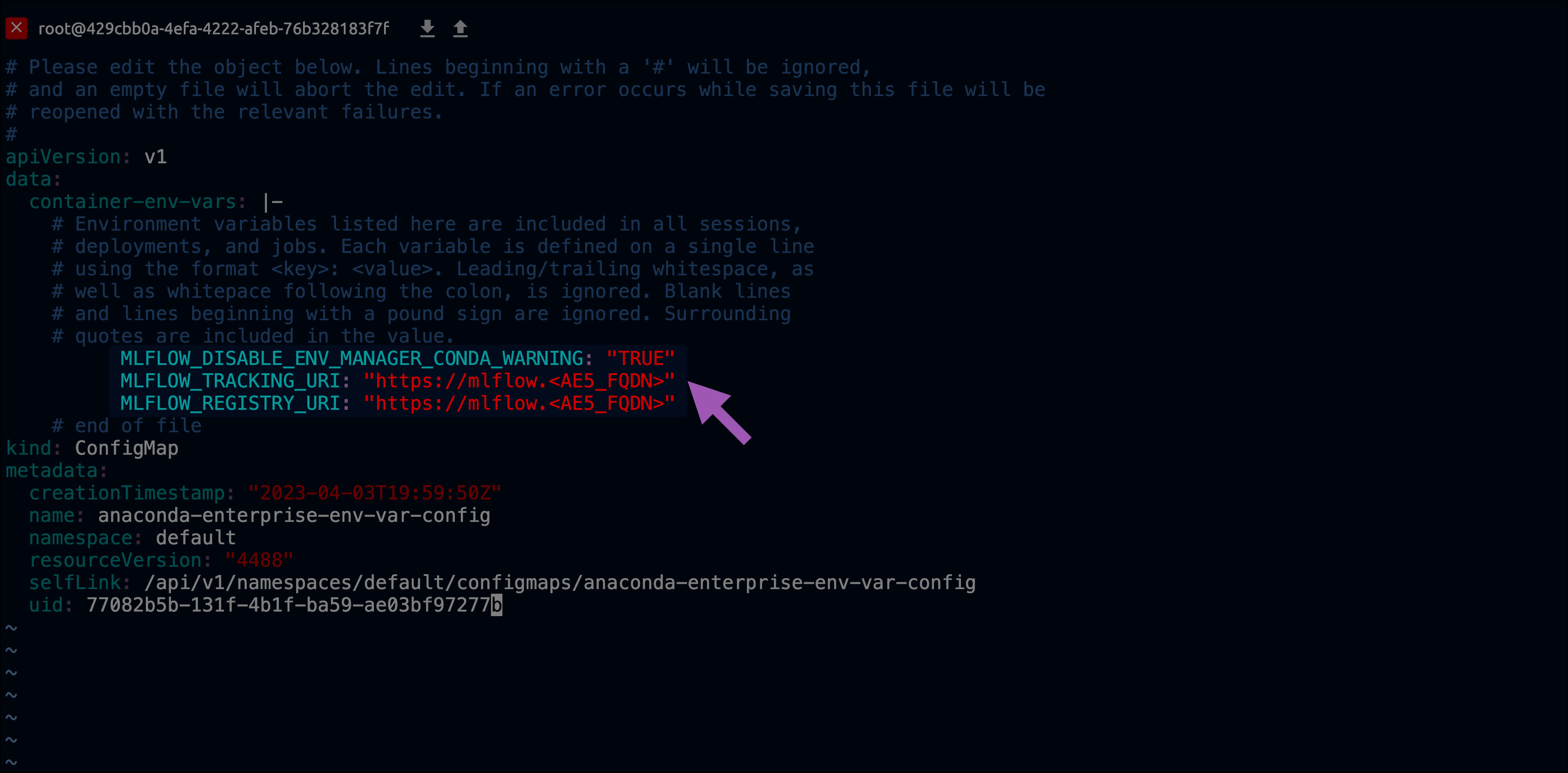
Save your work and close the file.
Update Anaconda Enterprise with your changes and restart services by running the following command:
kubectl get pods | grep 'ap-deploy\|ap-workspace' | cut -d' ' -f1 | xargs kubectl delete pods
Download MLflow#
Extract all files from the tarball you just downloaded.
Tip
Keep these somewhere that is easy for you to locate.
Install MLflow#
Open a browser and navigate to Anaconda Enterprise.
Log in as an administrator account with managed persistence permissions.
Click Create +, then select Upload Project from the dropdown menu.
Click Browse.
Locate the extracted files from your download and select the
MLflowTracking ServerProject-<VERSION>.tar.gzfile.Provide a name for your MLflow Server project.
Click Upload.

Open a session for your new MLflow Server project.
Upload the
migrate-<VERSION>.pyandanaconda-platform-mlflow-runtime-<VERSION>.tar.gzfiles to the root of the project.Caution
Do not commit changes to the project until instructed. If you attempt to commit too early, you will receive an error due to the size of the runtime file.
Open a terminal in your session, and run the following command:
# Replace <VERSION> with your release version python migrate-<VERSION>.py
Activate your new environment by running the following command:
conda activate /tools/mlflow/mlflow_env/
Verify your installation was successful by running the following command:
mlflow
Tip
If your install was successful, your command returns a list of available mlflow arguments.
Open the
anaconda-project.ymlfile in the project with your preferred file editor.Update the
MLFLOW_TRACKING_GC_TTLvalue to something that makes sense for your use case.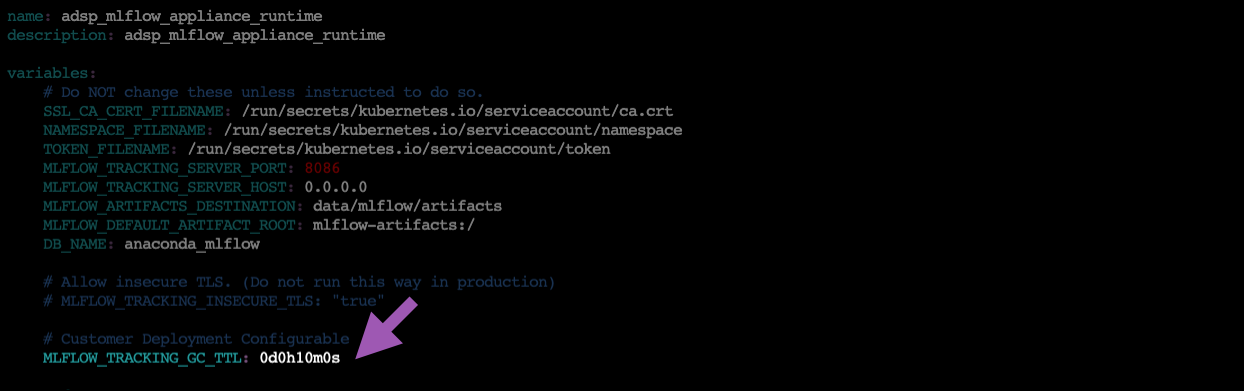
Note
The
MLFLOW_TRACKING_GC_TTLvariable instructs MLflow to perform garbage collection on deleted artifacts that have reached a specified age.Commit the changes you’ve made to the project.
Note
It is not necessary to commit the
migrate-<VERSION>.pyfile to the project. Once installation is complete, you can safely delete this file.Stop the project session.
Deploy MLflow#
Select Deployments from the left-hand navigation.
Click Deploy.
Enter a name for the deployment, set the static url to the same value used in your
anaconda-enterprise-env-var-config.ymlfile (https://mlflow.<AE5_FQDN>), and then click Deploy.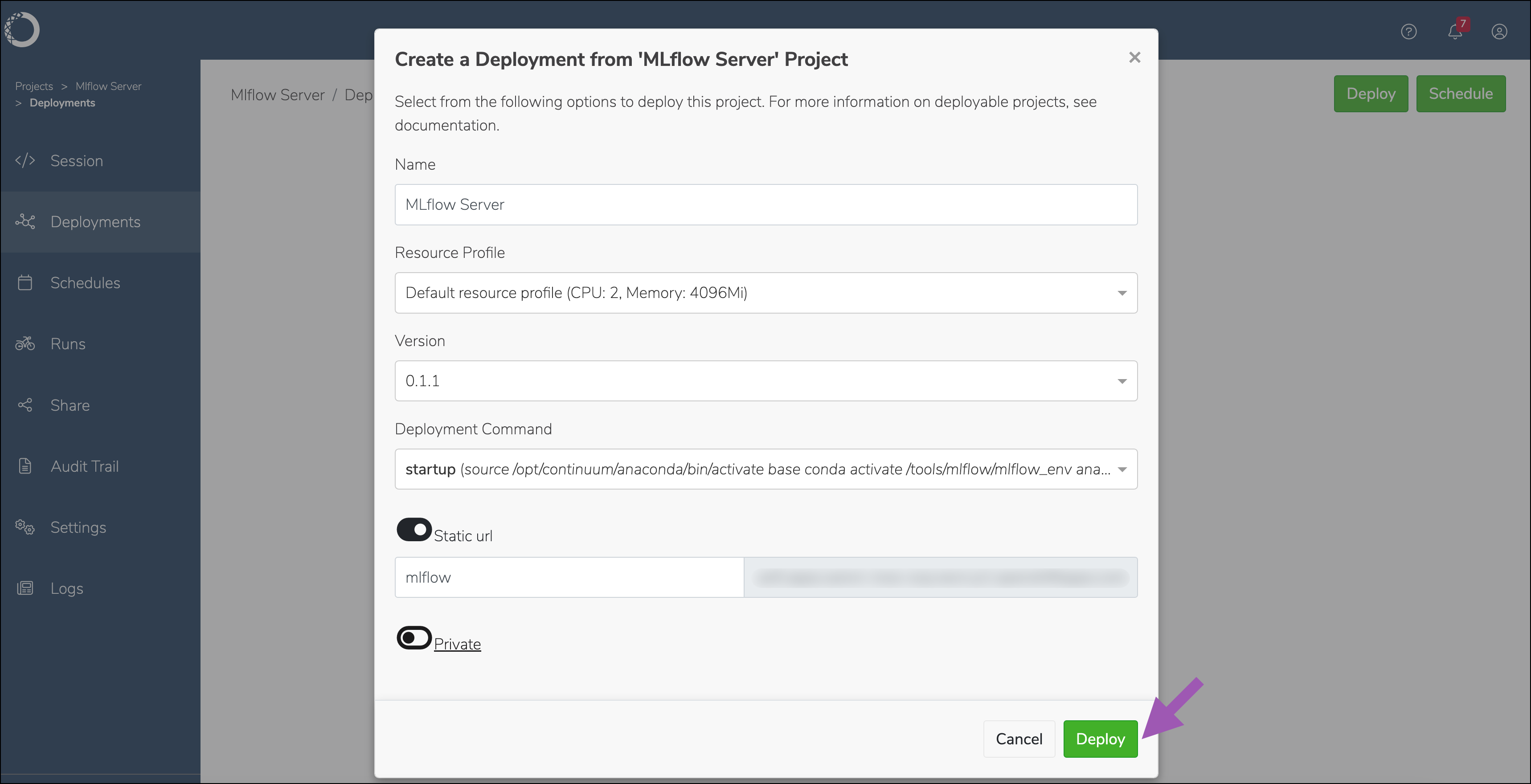
Provide Access#
Select the deployment you just created.
Select Share from the left-hand navigation menu.
Enter the names of users or groups to provide with permissions to access MLflow, then click Add.
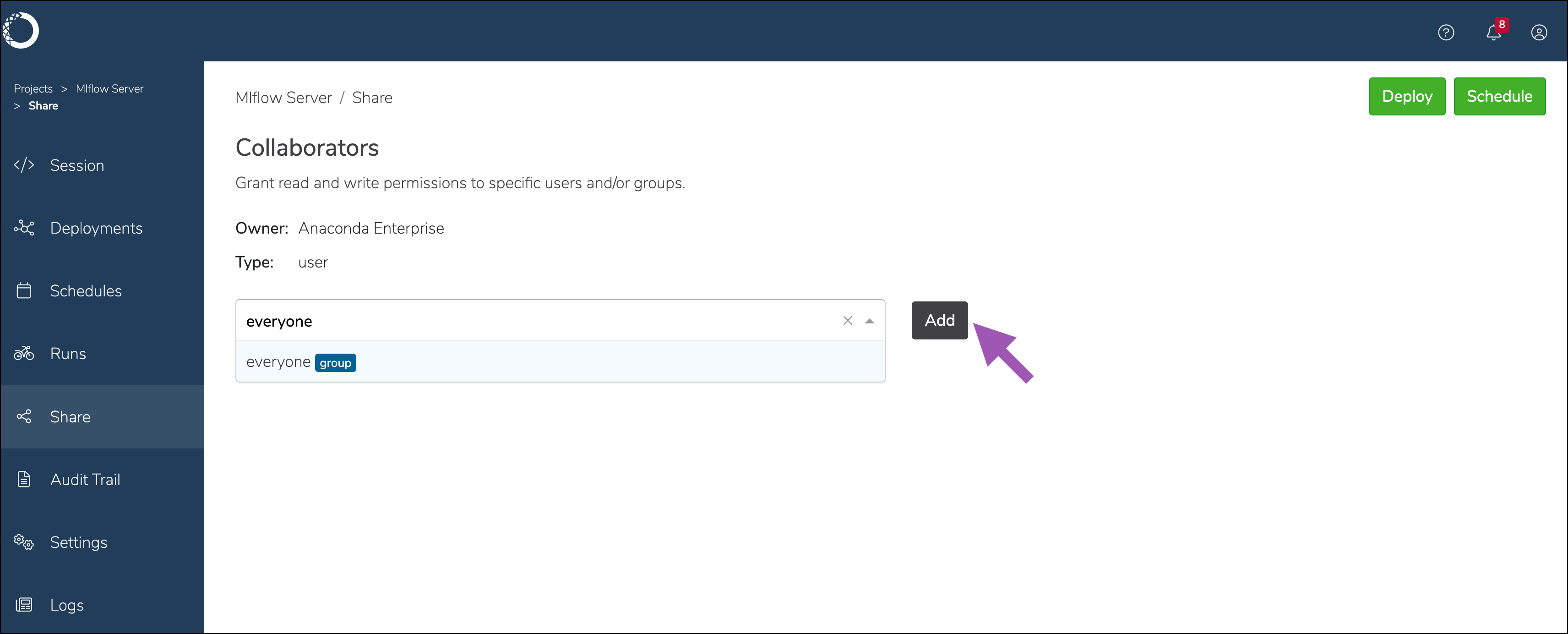
Note
This list populates from Keycloak.
Select Settings from the left-hand menu.
Click Generate to create a token for this deployment.
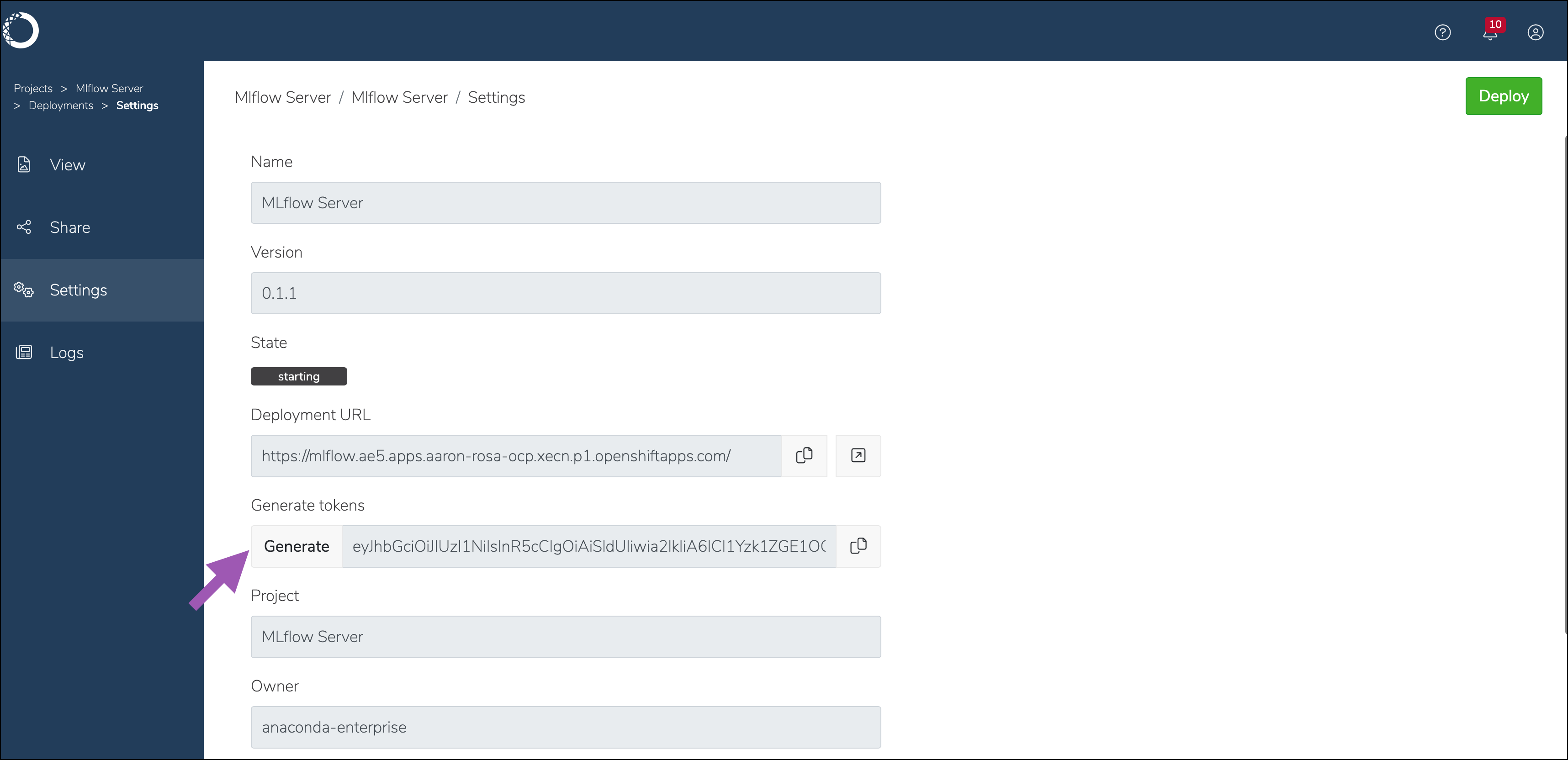
Note
Every user who needs API access to MLflow also requires this token. You must share this token manually.
The administrator of the MLFlow Tracking Server must generate and provide the access token each time the server is restarted.
Set up garbage collection#
When a client deletes a resource, MLflow transitions the resource into a deleted lifecycle state and hides it in the UI, but does not purge it from the system. Deleted resources will block creation of new resources with the same name until the garbage collection process has purged it.
The garbage collection process works in tandem with the MLFLOW_TRACKING_GC_TTL variable that is set in the anaconda-platform.yml project file. When a resource reaches the age specified by the MLFLOW_TRACKING_GC_TTL variable AND the garbage collection process runs, it will be purged.
Create a schedule within the MLflow Server project.
Name the schedule MLflow Garbage Collection.
Open the Deployment Command dropdown menu and select gc.
Schedule an interval to run the garbage collection. Custom schedules utilize cron expressions.
Click Schedule.

Upgrading MLflow#
Open a browser and navigate to Anaconda Enterprise.
Log in as an administrator account with managed persistence permissions.
Open your MLflow Server project.
Select Deployments from the left-hand navigation.
Terminate your current deployment.
Select Schedules from the left-hand navigation.
Pause all shceduled runs.
Start a new session in your MLflow Server project.
Upload your newly obtained
migrate-<VERSION>.pyandanaconda-platform-mlflow-runtime-<VERSION>.tar.gzfiles to the root of the project.Open a terminal in your project and run the following command:
# Replace <VERSION> with your release version python migrate-<VERSION>.py
Redeploy your MLflow Server project.
Generate a new token to share your deployment.
Note
Remember, you must generate an access token and provide it to users each time the server is restarted!
Restart all scheduled runs.