Migrating from Anaconda Enterprise 4 to Workbench#
The process of migrating from Anaconda Enterprise 4 to Data Science & AI Workbench involves the following tasks:
For Administrators:
Export all packages and package information from your Anaconda Enterprise 4 Repository.
Import the packages into Workbench.
For Notebook users:
Export each project environment to a
.ymlfile.Convert each project into a format compatible with Workbench.
Due to architectural changes between versions of the platform, there are some additional steps you may need to follow to migrate code between Anaconda Enterprise 4 and Workbench. These steps vary, based your current and new platform configurations.
Exporting packages#
Workbench enables you to create a site dump of all packages used by your organization, including the owners and permissions associated with each package.
Log in to the Anaconda Enterprise 4 Repo and switch to the
anaconda-serveruser.To export your packages, run the following command on the server hosting your Anaconda Enterprise 4 Repository:
anaconda-server-admin export-site
Running this command creates a directory structure containing all files and user information from your Anaconda Enterprise 4 Repository. For example:
site-dump/
├── anaconda-user-1
│ ├── 59921152446b5703f430383f--moto
│ ├── 5992115f446b5703fa30383e--pysocks
│ └── meta.json
├── anaconda-organization
│ ├── 5989fbd1446b575b99032652--future
│ ├── 5989fc1d446b575b99032786--iso8601
│ ├── 5989fc1f446b575b990327a8--simplejson
│ ├── 5989fc26446b575b99032802--six
│ ├── 5989fc31446b575b990328b0--xz
│ ├── 5989fc35446b575b990328c6--zlib
│ └── meta.json
└── anaconda-user-2
└── meta.json
Each subdirectory of site-dump contains the contents of the Repository as it pertains to a particular user. For example anaconda-user-1 has two packages, moto and pysocks. The meta.json file in each user directory contains information about any groups of end users that user belongs to, as well as their organizations.
Package directories contain the package files, prefixed with the id of the database. The meta.json file in each package directory contains metadata about the packages, including version, build number, dependencies, and build requirements.
Note
Other files included in the site-dump—such as projects and environments—are NOT imported by the package import tool. That’s why users have to export their Notebook projects separately.
Importing packages#
You can choose whether to import packages into Workbench by username or organization, or import all packages.
Before you begin:
Anaconda recommends you compare the import options before proceeding, so you can choose the option that most closely aligns with the desired outcome for your organization.
You’ll be using the Workbench command line interface (CLI) to import the packages you exported, so be sure to install the Workbench CLI if you haven’t already.
Log in to the command line interface using the following command:
anaconda-enterprise-cli login
Follow the instructions below for the method you want to use to import packages.
To import packages by username or organization:
As you saw in the example above, the packages for each user are put in a separate directory in the site-dump. This means that the import process is the same whether you specify a directory based on a username or organization.
Import a single directory from the site-dump using the following command:
anaconda-enterprise-cli admin import site-dump/name
Replacing name with the actual name of the directory you want to import.
Note
You can also pass a list of directories to import.
To import all packages:
Run the following command to import all packages in the site dump:
anaconda-enterprise-cli admin import site-dump/*
How channels of imported packages are named
When you import packages by username, a new channel is created for each unique label the user has applied to their packages, using the username as a prefix. (The default package label “main” is not included in channel names.)
For example, if anaconda-user-1 has the following packages:
moto-0.4.31-2.tar.bz2with labelmainpysocks-1.6.6-py35_0.tar.bz2with labeltest
The following channels are created:
anaconda-user-1containing the package filemoto-0.4.31-2.tar.bz2anaconda-user-1/testcontaining the package filepysocks-1.6.6-py35_0.tar.bz2
When you import all packages in an organization, a new channel is created for each organization, group, and label. The script appends any groups associated with the organization to the channel name it creates. (The default package label “main” and default organization label “Owner” are not included in channel names.)
For example, if anaconda-organization includes a group called Devs, and the site dump for anaconda-organization contains a package file named xz-5.2.2-1.tar.bz2 with the label Test, running the script will create the following channels:
anaconda-organization– This channel contains all packages that the organization owner can access.anaconda-organization/Devs– This channel contains all packages that theDevgroup can access.anaconda-organization/Devs/Test– This channel contains all packages labeledTestthat theDevgroup can access.
Granting access to channels and packages
After everything is uploaded, each channel created as part of the import process is shared with the appropriate users and groups. In the case of the example above,``anaconda-user-1`` is granted read-write access to the anaconda-user-1 and anaconda-user-1/test channels, and all members of the Devs group will have read permission for everything in the Devs channel.
You can change these access permissions as needed using the Workbench UI or CLI. See Managing channels and packages for more information.
Migrating Anaconda Enterprise 4 Notebook Projects#
Before you begin:
If your project refers to channels in your on-premises repository or other channels in anaconda.org, ask you System Administrator to mirror those channels and make them available to you in Workbench.
If your project use non-conda packages, you’ll need to upload those packages to Workbench.
If your notebook refers to multiple kernels or environments, set the kernel to a single environment.
If your project contains several notebooks, verify that they all are using the same kernel or environment.
Exporting your project#
Exporting a project creates a yml file that includes all the environment information for the project.
Log in to your Anaconda Enterprise 4 Notebooks server.
Open a terminal window and activate conda environment 2.6 for your project.
Install
anaconda projectin the environment:conda install anaconda-project=0.6.0
If you get a
not foundmessage, install it from anaconda.org:conda install -c anaconda anaconda-project=0.6.0
Export your environment to a file:
conda env export -n default -f _env.yml
<default>is the name of the environment where the notebook runs.Verify that the format of the environment file looks similar to the following, and that the dependencies for each notebook in the project are listed:
yaml channels: - wakari - r - https://conda.anaconda.org/wakari - defaults - anaconda-adam prefix: /projects/anaconda/MigrationExample/envs/default dependencies: - _license=1.1=py27_1 - accelerate=2.3.1=np111py27_0 - accelerate_cudalib=2.0=0 - alabaster=0.7.9=py27_0 # ... etc ...
If it contains any warning messages, run this script to modify the encoding and remove the warnings:
import ruamel_yaml with open("_env.yml") as env_fd: env = ruamel_yaml.load(env_fd) with open("environment.yml", "w") as env_fd: ruamel_yaml.dump(env, env_fd, Dumper=ruamel_yaml.RoundTripDumper)
Converting your project#
To create a project that’s compatible with Workbench, perform these steps:
Run the following command from an interactive shell:
anaconda-project init
Anaconda Enterprise 4 supports Linux only, so run the following command to remove the Windows and MacOS platforms from the project’s
anaconda-project.ymlconfiguration file:anaconda-project remove-platforms win-64 osx-64
Run the following command to verify the platforms were removed:
anaconda-project list-platforms
Add
/.indexer.pidand.gitto the.projectignorefile.Run the following command to compress your project:
# Replace <FILENAME> with a name for your project archive file anaconda-project archive <FILENAME>.tar.gz
Caution
Project names cannot contain spaces or special characters. There is a 1GB size limit for project archive files.
In Anaconda Enterprise 4 Notebooks, from your project home page, open the AEN Workbench. Locate your project file (e.g.,
AENProject.tar.gzin the image below) in the file list, right-click and select Download.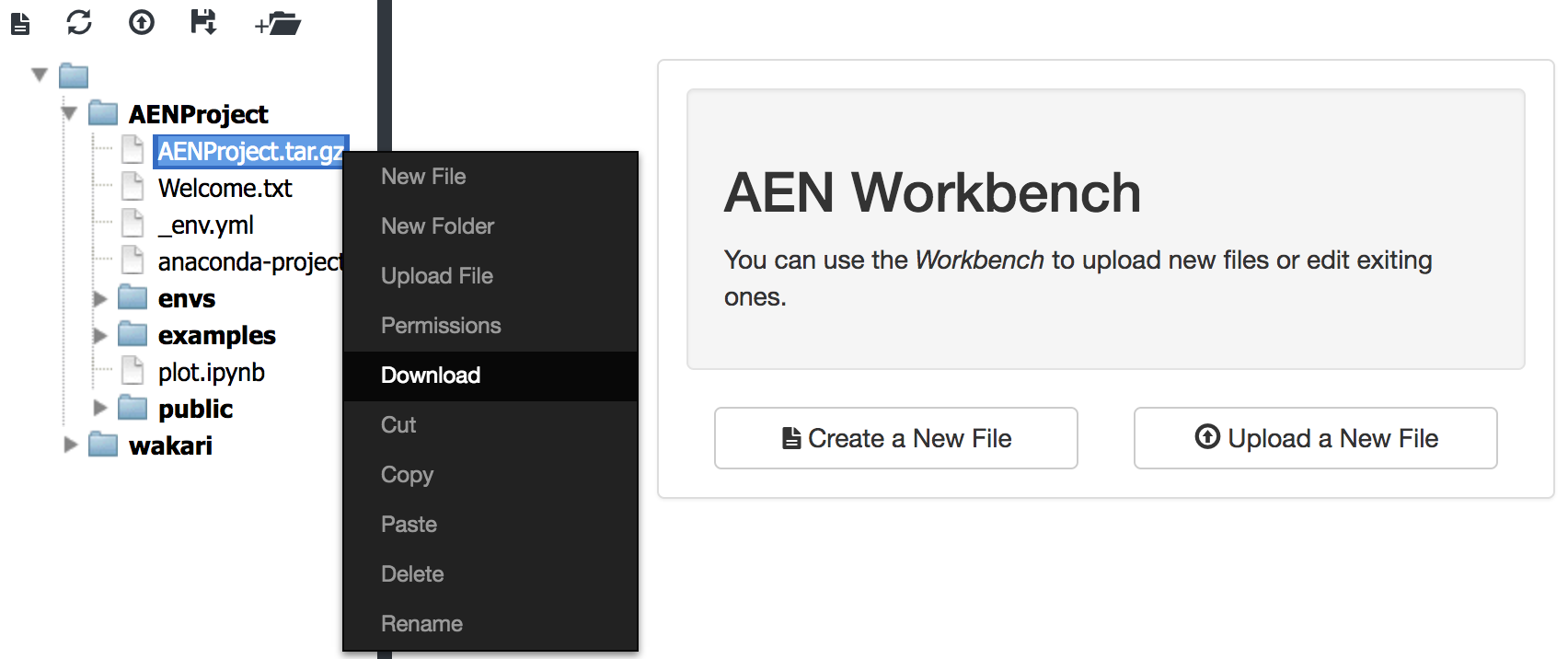
Now your project is ready to be uploaded into Workbench.
Uploading your project to Workbench#
Log in to Workbench and upload your project archive file <FILENAME>.tar.gz. See Working with projects for help.
Note
To maintain performance, there is a 1GB file size limit for project files you upload. Workbench projects are based on Git, so Anaconda recommends you commit only text-based files relevant to a project, and keep them under 100MB. Binary files are difficult for version control systems to manage, so Anaconda recommends using storage solutions designed for that type of data, and connecting to those data sources from within your sessions.
Migrating code#
Anaconda Enterprise 4 and Workbench are based on a different architecture. This means that code inside your Anaconda Enterprise 4 notebooks might not run as expected in Workbench. Anaconda Enterprise 4 sessions ran directly on the host filesystem, where the libraries, drivers, packages, and connectors required to run them were available. Workbench sessions run in isolated containers with their own independent file system, so they don’t necessarily have access to everything on the host.
This difference in architecture primarily impacts the following:
Connecting to external data sources#
If you currently rely on ODBC/JDBC drivers to connect to specific databases such as Oracle and Impala, Anaconda recommends you use services that support this, such as Apache Impala and Apache Hive, instead. Additionally, using a language and platform agnostic connector such as Thrift allows you to create reproducible code that is more portable.
For best practices on how to connect to different external systems inside Workbench, see Connecting to the Hadoop and Spark ecosystem.
Service/System |
Recommended |
|---|---|
Apache Impala |
|
Apache Hive |
|
Oracle |
build conda package with their driver |
If this is not possible, Anaconda recommends you obtain or build conda packages for the connectors and drivers you need. This enables you to add them as package dependencies for your project that will be installed when you start a Notebook session or deploy the project.
This has the added benefit of enabling you to update dependencies on connectors on a per-project basis.
Installing external dependencies#
If you typically install dependencies using system package managers such as apt and yum, you can continue to do so in Workbench. Dependencies installed from the command line are available during the current session only, however.
If you want them to persist across project sessions and deployments, add them as packages in the project’s anaconda-project.yml configuration file. See Configuring project settings for more information.
If your project depends on a package that is not available in your internal Workbench Repository, search anaconda.org or build your own conda package using conda-build, then upload the conda package to the Workbench repository.
If you don’t have the expertise required to build the custom packages your organization needs, consider engaging our consulting team to make your mission-critical analytics libraries available as conda packages.